What is an AWS Sagemaker Notebook Instance?
An Amazon SageMaker notebook instance is a compute instance that runs a Jupyter notebook application, letting you run machine learning models in the cloud. SageMaker creates and manages these instances and the resources they require. You can use Jupyter notebooks on a SageMaker notebook instance to prepare and process data, write code to train models, deploy models to SageMaker hosting, and test or validate models.
Related content: Read our guide to AWS SageMaker
In this article:
How Amazon SageMaker Notebook Instances Work
When running a SageMaker notebook instance, you can choose one of several instance types, depending on how you are using the notebook instance. You must ensure that the notebook instance has sufficient memory, CPU, and I/O for your machine learning models:
- If you are loading datasets into the memory of your notebook instance for retrieval or preprocessing, ensure you use an instance type that has enough RAM to support your dataset. Typically, this will require an instance with at least 16 GB of memory (.xlarge or larger).
- If you are using notebooks for compute-intensive preprocessing, prefer a compute-optimized instance like c4 or c5.
You can use SageMaker to orchestrate other AWS services. For example, you can use a notebook instance to perform extract, transform, load (ETL) operations via AWS Glue, or perform mapping and data reduction via Amazon EMR.
You can also use other AWS services as extensions of your notebook instance, which provide additional temporary storage space or computing resources. For example, you can use Amazon S3 buckets to store and retrieve training and test data.
Related content: Read our guide to SageMaker Notebook (coming soon)
SageMaker Initialization Process
When SageMaker receives a request for a new notebook instance, it goes through the following stages to setup and initialize the instance:
- If you selected this in the instance configuration, SageMaker creates a network interface in your virtual private cloud (VPC). The subnet ID specified in the request is used to determine the Availability Zone and security group in which the subnet will be created.
- SageMaker launches compute instances in your SageMaker VPC. It performs configuration tasks to manage notebook instances and, if you specify a VPC, enables traffic between the VPC and notebook instances.
- SageMaker installs Anaconda Packages and libraries for popular deep learning platforms.
- SageMaker attaches storage volumes—you can use these volumes as a workspace to organize training datasets, validations, tests, or to temporarily store other data. Volume size can be between 5 GB and 16384 GB in 1 GB increments.
- SageMaker copies the Jupyter Notebook example. This is a Python code example that demonstrates how to train and host a model using various algorithms and training datasets.
Tutorial: Create an Amazon SageMaker Notebook Instance
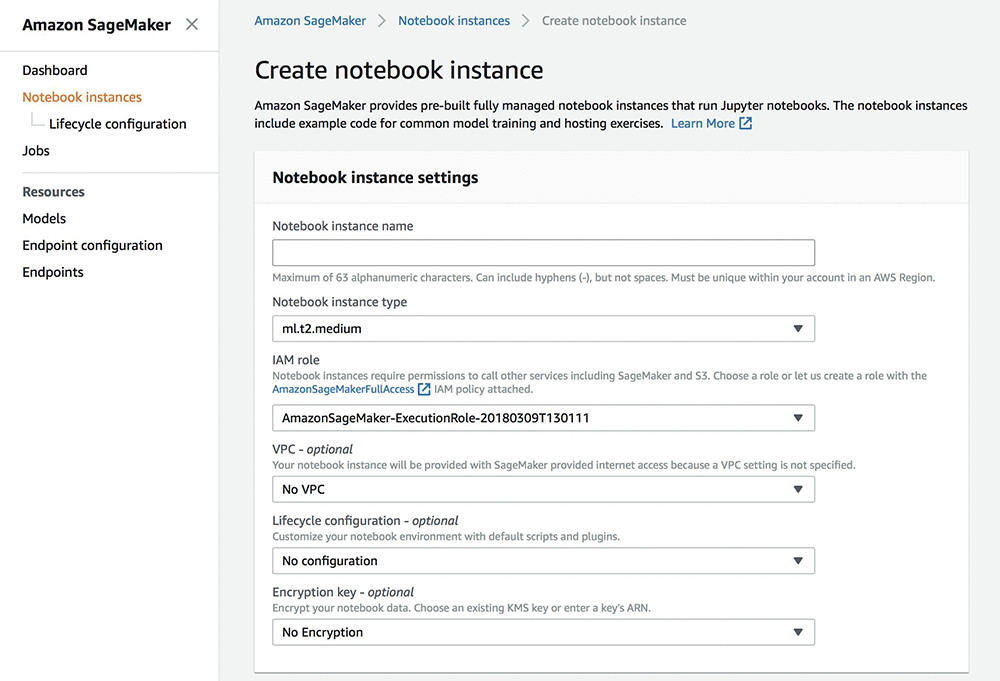
Here is a step-by-step process that explains how to create a SageMaker notebook instance:
- Go to the Amazon SageMaker console: https://console.aws.amazon.com/sagemaker/.
- Select the Notebook instances option, and then select Create notebook instance.
- Go to the Create notebook instance page and provide the requested information. You can leave the default values if a certain field is not mentioned. Here are the values you need to enter:
a) Notebook instance name—input a descriptive name for the notebook instance.
b) Notebook Instance type—for this exercise, choose ml.t2.medium, which is the least expensive instance type.
c) Platform Identifier—select a platform type for the notebook instance. The platform type determines a specific operating system and JupyterLab version for the notebook instance.
d) IAM role—select the Create a new role option, and then Create role. This IAM role comes with permissions to access all S3 buckets that include SageMaker in the name. The AmazonSageMakerFullAccess policy that SageMaker attaches to each role provides these IAM role permissions.
e) Select Create notebook instance.

Image Source: AWS
SageMaker takes a few minutes and then launches a machine learning compute instance—a notebook instance. SageMaker attaches a 5 GB of Amazon EBS storage volume to the notebook instance, as well as a preconfigured Jupyter notebook server, a set of Anaconda libraries, and SageMaker and AWS SDK libraries.
Customize a Notebook Instance Using a Lifecycle Configuration Script
SageMaker lifecycle configuration allows you to customize notebook instances to your needs. You can use it to:
- Install packages or sample notebooks
- Configure security
- Set up networking
- Control other Amazon resources, such as EMR instances
- Run any shell script to customize the instance
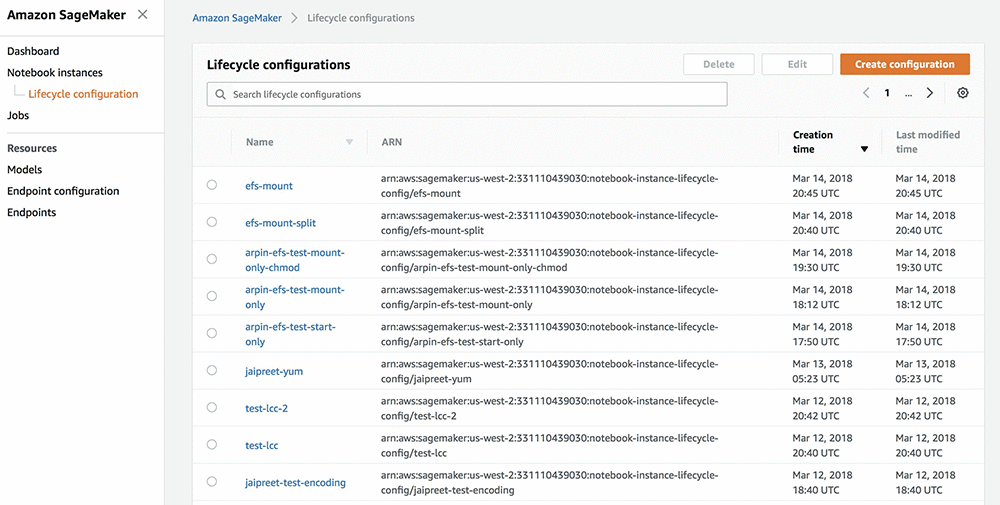
Lifecycle configuration runs specific shell scripts when you create or start a notebook instance. When creating a new instance, you can define a new lifecycle configuration or reuse one from a previous instance.
In the SageMaker console, navigate to Notebook instances > Lifecycle configuration to see previous lifecycle configurations you created.

Image Source: AWS
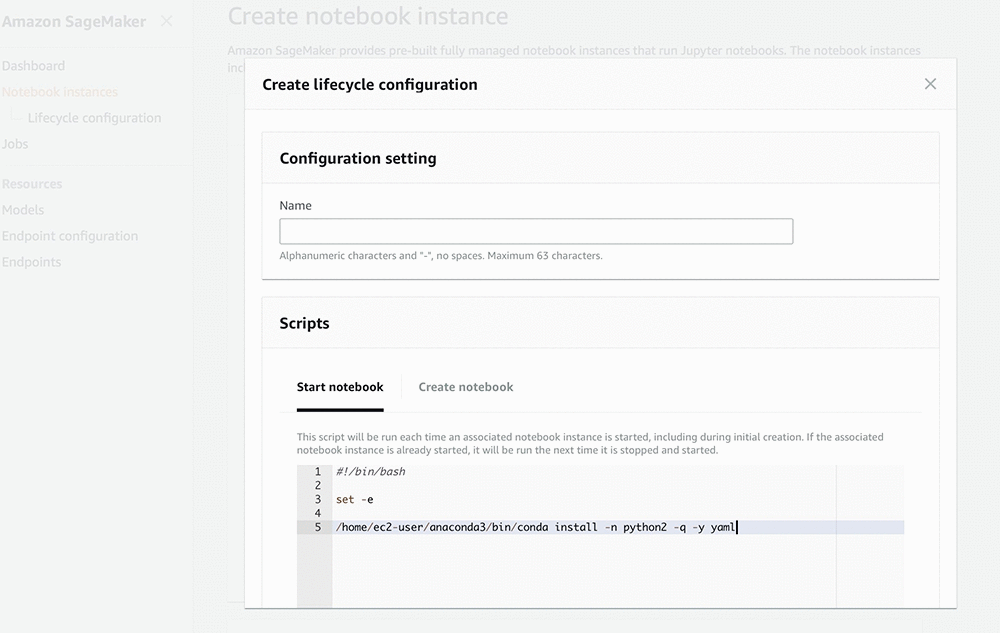
To create a new lifecycle configuration:
1. Open the SageMaker console and select Notebook instances> Lifecycle configuration. Click the Create configuration button.

Image Source: AWS
2. Type a name for the configuration.
3. Add a script under one of the two sections below:
a) Click Start notebook and add a custom script to run it each time the notebook runs
b) Click Create notebook and add a custom script to run it only once when the notebook is created.
4. Click Create configuration. From now on you can apply this lifecycle configuration to any notebook instance you create.
SageMaker Notebook with Run:ai
When using AWS SageMaker, your organization might run a large number of machine learning experiments requiring massive amounts of computing resources. Run:ai automates resource management and orchestration for machine learning infrastructure. With Run:ai, you can automatically run as many compute intensive experiments and inference workloads as needed.
Here are some of the capabilities you gain when using Run:ai:
- Advanced visibility—create an efficient pipeline of resource sharing by pooling GPU compute resources.
- No more bottlenecks—you can set up guaranteed quotas of GPU resources, to avoid bottlenecks and optimize billing.
- A higher level of control—Run:ai enables you to dynamically change resource allocation, ensuring each job gets the resources it needs at any given time.
Run:ai simplifies machine learning infrastructure pipelines, helping data scientists accelerate their productivity and the quality of their models.
Learn more about the Run:ai GPU virtualization platform.


{kind=link}
{kind=link}
{kind=link}