What Is Slurm?
Slurm is a system for managing and scheduling Linux clusters. It is open source, fault tolerant and scalable, suitable for clusters of various sizes.
When Slurm is implemented, it can perform these tasks:
- Assign a user to a compute node. The access provided can be exclusive, with resources being limited to an individual user, or non-exclusive, with the resources shared among multiple users.
- Provide the framework for launching and monitoring jobs on assigned nodes. The jobs are typically managed in parallel, running on multiple nodes.
- Manage the pending job queue, determining which job is next in line to be assigned to the node.
Slurm also offers an option to add plugin extensions. You can use ready-made plugins or build them yourself through the API. Plugins can provide capabilities such as:
- Authentication and Authorization
- Job logging
- Various security measures
- Energy management
- Topology-based scheduling
While Slurm is a mature, massively scalable system, it is becoming less relevant for modern workloads like AI/ML applications. We’ll explain the basics of Slurm, compare it to modern orchestrators like Kubernetes, and explain the challenges of using Slurm for AI/ML workloads.
This is part of an extensive series of guides about open source
In this article:
Slurm Architecture
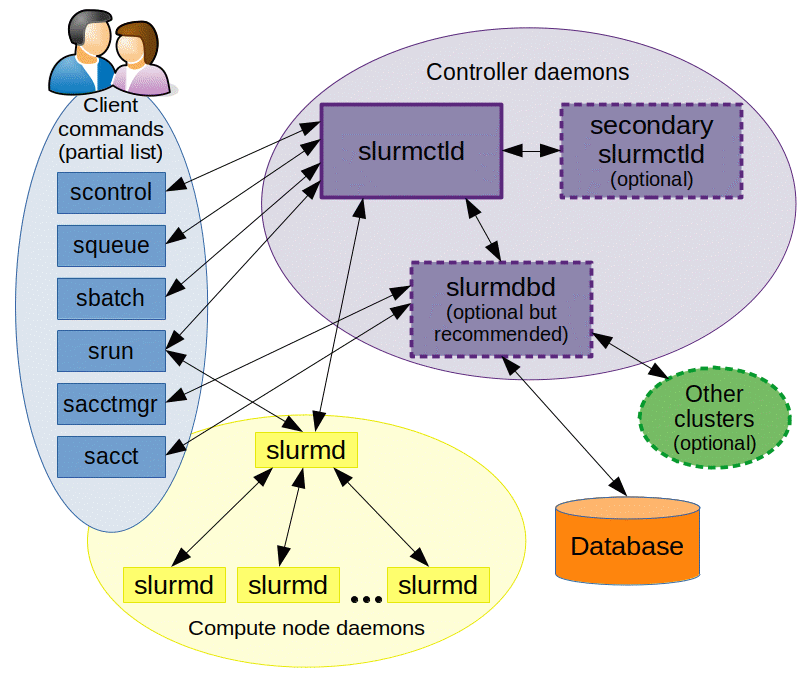
Slurm monitors resources and jobs through slurmctld (the centralized manager) and can use a backup manager in case of failure. Each node has a slurmd (a daemon), which waits for jobs, executes them and returns their status, via fault-tolerant communication.
The optional database daemon, or slurmdbd, records accounting information for multiple Slurm-managed clusters in a single database. The REST API daemon, slurmrestd, allows interaction with Slurm through a REST API.
Users can initiate, manage and terminate jobs using the following commands:
- srun—launches jobs
- scancel—cancels jobs
- sinfo—for system status
- squeue—for status of pending job
- sacct—for completed or running jobs
- sview—graphic status report showing network topology
- scontrol—cluster configuration and monitoring tool
- sacctmgr—database administrative tool
- sbatch – submit a batch script

Image Source: Slurm
Slurm Plugins
Slurm offers a general plugin mechanism to facilitate various integrations. This allows you to use a building block strategy for a range of Slurm configurations. Examples of plugins include:
- Accounting storage—stores historical job data
- Containers—supports HPC container workloads
- Generic resources—an interface for controlling resources such as GPUs and MIC processors
- Message passing interface (MPI)—provides various hooks for different MPI implementations
- Priority—prioritizes jobs throughout their lifecycle
- Scheduler—determines when jobs are scheduled
- Network topology—facilitates optimization of resource selection
The Slurm daemons manage entities such as:
- Nodes—computer servers
- Partitions—used to logically group nodes
- Jobs—assignments of a resource to a user for a set duration
- Job steps—tasks within the jobs, often in parallel
Slurm vs Kubernetes Scheduler
Kubernetes is an open-source container orchestration solution, and its default scheduler is kube-scheduler. Thus, kube-scheduler is the natural choice for managing flexible, container-based workloads. Slurm is the default scheduler for typical HPC environments, suitable for managing distributed batch-based workloads.
The strength of Slurm is that it can integrate with popular frameworks such as ALPS (Application Launch and Provisioning System), which enables the management of runtimes and deployment of applications at scale.
Kubernetes, on the other hand, allows you to manage containerized workloads and cloud-based technologies, which supports more scalable applications.
Learn more in our detailed guide to Slurm vs Kubernetes
What Is Slurm Missing for AI/ML Workloads?
The flexibility of Slurm allows it to run any workload supported by Linux, including AI/ML workloads such as deep learning algorithms. To train a large AI/ML algorithm, you just need to load its runtime on the cluster, and Slurm will handle the scheduling. However, scheduling is just one aspect of managing AI/ML workloads, so while Slurm’s cluster scheduling capability is a good foundation, it is not everything.
Related content: Read our guide to Slurm for machine learning
The following capabilities offer benefits for machine learning engineers.
Building Models
Large Slurm clusters allow machine learning engineers to schedule jobs on GPUs, which they can theoretically leverage to accelerate the training of a model. To achieve this, the end-user works with Slurm Generic Resources (GRES), and needs to manipulate fragile environment variables to enable CUDA support, which is cumbersome and unreliable. The alternative is to directly configure the model code in Horovod, which is also complicated, and often results in model porting issues that are difficult to debug.
Tuning hyperparameters allows you to optimize the predictive performance of an AI/ML model, but Slurm doesn’t offer any tooling for this. This means you have to integrate a specialized hyperparameter tuning tool, or else tune the model yourself. Integrating such tools can be complicated and create lags, because the machine learning engineer usually has to interact with Slurm concepts and APIs.
In addition, Slurm does not provide tooling for running machine learning pipelines, which is now broadly supported by open source tools like MLFlow and Kubeflow. Slurm is also very inefficient when scheduling resources for a pipeline with different tasks that require different resources. Slurm uses a static resource allocation model, which makes it really difficult to orchestrate tasks dynamically such that each task is allocated the appropriate type and amount of resources.
Related content: Read our guide to Slurm GPU
Automated Tracking
Machine learning engineers have to track a range of metadata, including validation and training metrics, model checkpoints, application and system logs, and event data. Slurm doesn’t support tracking for all these metadata types, which may require the use of specialized tools that do not integrate with Slurm (e.g. MLflow). If tracking and data storage are managed ad hoc, this can result in inconsistencies across your workloads.
Execution and Scheduling
Out of the box, Slurm does not support pausing and restarting of jobs – if a job is paused, all progress is lost. This means that the Slurm user must implement jobs in such a way that they can be paused at checkpoints and restarted.
This is difficult to do for AI/ML workloads, so engineers usually avoid it, preferring to cancel or reboot jobs. If you don’t pause long-running jobs, they make resources unavailable for shorter jobs and can result in GPU-hogging queues.
User Experience and Interface
Machine learning engineers can benefit from a user-friendly interface that abstracts low-level infrastructure concepts. Typically, a machine learning engineer wraps Python in a Slurm script specifying required resources, the runtime and the executable, then launches the workload from a login node using CLI commands like srun and sbatch.
Slurm can provision resources and schedule jobs, but managing and tracking assets requires the use of an interface. Most interfaces (such as those specific to TensorFlow) don’t offer all the necessary features. AI/ML on Slurm can differ significantly according to the ML library used.
Run:ai – A Scheduler Built for AI/ML Workloads
Run:ai Scheduler lets you combine the power of Kubernetes with the advanced scheduling features of Slurm.
Run:ai automates resource management and orchestration for AI workloads that utilize distributed infrastructure on GPU in HPC data centers. With Run:ai, you can automatically run as many compute intensive workloads as needed on GPU in your HPC infrastructure.
Here are some of the capabilities you gain when using Run:ai:
- Advanced visibility—create an efficient pipeline of resource sharing by pooling compute resources.
- No more bottlenecks—you can set up guaranteed quotas of resources, to avoid bottlenecks and optimize billing in cloud environments.
- A higher level of control—Run:ai enables you to dynamically change resource allocation, ensuring each job gets the resources it needs at any given time.
Run:ai accelerates deep learning and other compute intensive workloads, by helping teams optimize expensive compute resources.
Learn more about the Run:ai Kubernetes Scheduler
Learn More About Slurm
There’s a lot more to learn about Slurm. To continue your research, take a look at the rest of our guides on this topic.
Slurm vs LSF vs Kubernetes Scheduler: Choosing the Right HPC Scheduler
HPC and AI run massive amounts of jobs simultaneously. Learn about the top schedulers, how they differ and which to choose. This article provides an in-depth overview and comparison of three popular schedulers—Slurm Workload Manager, IBM Platform Load Sharing Facility (LSF), and Kubernetes kube-scheduler functionality.
Read more: Slurm vs LSF vs Kubernetes Scheduler: Which is Right for You?
4 Reasons Slurm Underperforms when Tackling Deep-Learning Workloads
In this post, we’ll look at some of the unique challenges posed by DL workloads. We’ll then examine four reasons Slurm underperforms when tackling those workloads. We’ll also explore how you can simplify all your DL workloads to get better results quicker, while taking advantage of all the resources available.
Read more: 4 Reasons Slurm Underperforms when Tackling Deep-Learning Workloads
See Additional Guides on Key Open Source Topics
Together with our content partners, we have authored in-depth guides on several other topics that can also be useful as you explore the world of open source.
Kubernetes Architecture
Authored by Run:ai
- What is Kubernetes Architecture?
- Kubernetes Scheduling for AI
- Kubeflow Pipelines: The Basics and a Quick Tutorial
RTOS
Authored by Sternum
- What Is RTOS, How It Works, and 9 RTOS Platforms to Know
- Yocto Project: Components, Use Cases, and a Quick Tutorial
- Zephyr Real-Time Operating System: Features, Benefits & Challenges
Openshift Container Platform
Authored by NetApp


{kind=link}