
Ready for a demo of Run:ai?
In our previous results explained in the white paper, we found a direct correlation between increased GPU memory and enhanced inference throughput. This connection comes from the ability to run Large Language Models (LLMs) with a bigger Key-Value (KV) cache and leverage larger batch sizes. However, there's a point where the throughput stabilizes even if the batch size is increasing. This happens when we shift from the memory-bound regime into the compute-bound regime, a phenomenon also highlighted in other resources (see Figure 1 and here). The memory-bound regime happens typically when the batch size is relatively small and data movements in the different GPU memory hierarchies are the bottleneck. The compute-bound phase starts when the compute operations become the bottleneck, especially with larger batches.
After noticing this pattern, we got curious about how using multiple GPUs for inference would impact throughput, even when the model fits on a single GPU. Our idea was to leverage model parallelism techniques to split the model parameters into multiple GPUs so as to increase the available memory in each GPU for KV cache (see Figure 2). In this case, batch size per GPU can be much larger compared to the single-GPU case, meaning more compute operations and higher throughput per GPU can be achieved at the expense of extra communication between the GPUs. In the memory-bound regime, the gain from increased compute operations can be much larger than the communication overhead, potentially leading to overall positive throughput gain.
In our experiments, we found out that multi-GPU serving can significantly enhance the inference throughput per GPU. Using tensor parallelism can increase the throughput per GPU by 57% for vLLM and 80% for TensorRT-LLM, while we also see impressive performance increase with latency. This made us realize that multi-GPU inference setups should not only be considered by practitioners when the model doesn’t fit into a single GPU but also for reducing latency and in the memory-bound regime, for increasing throughput.
In this post, we discuss the effects on throughput and latency when deploying different numbers of GPUs using vLLM and TensorRT-LLM together with different parallelism techniques in multi-GPU setups. From the memory-bound regime to the influence of parallelism on throughput and latency, we aim to provide a better understanding for researchers and engineers exploring the inference world of the large-scale language models across multiple GPUs.


Experiment Setup
Our focus on parallelism techniques honed in on two engines: vLLM and TensorRT-LLM (TRT-LLM). Due to a GPU shortage of A100 GPUs, our experiments centered around 4 NVIDIA V100 GPUs on a single node, each with 16 GB of memory. Here is more information about our setup:
Hardware:
Resources:
- CPU: 16 Cores
- Memory: 60 GB
- GPU: 4 x NVIDIA V100 (16GB)
Model:
- Architecture: Llama 2
- Variation: 7b-chat
- Checkpoint: NousResearch/Llama-2-7b-chat-hf
- Precision: float16
- Batch size: in all experiments we’ve increased the batch size to its maximum value
- Input / output sequence length = 128 tokens
- Query rate = 32 queries per second
Note: The absence of TGI support for NVIDIA V100 GPUs directed our focus to vLLM and TensorRT-LLM.
Tensor Parallelism vs. Pipeline Parallelism
Two parallelism techniques took center stage: tensor parallelism (TP) and pipeline parallelism (PP). TensorRT-LLM supported both, while vLLM only supported tensor parallelism. Our experiments were constrained to using tensor parallelism with vLLM. If you are new to the parallelism techniques, please refer to our blog post that explains different parallelism techniques.

Note: The information on Table 1 reflects the current offerings of the engines at the time of writing.
Exploring Latency in Multi-GPU Inference
Our initial experiments focused on measuring time per output token (TPOT), also known as latency. It's important to note that different sources may calculate latency differently (refer to this link for more details). The first significant finding emerged in our examination of vLLM. In vLLM, an increased degree of tensor parallelism resulted in higher latency due to Python overhead. In contrast, TensorRT-LLM, which is implemented in C++, demonstrated substantial improvements as tensor parallelism increased. When employing pipeline parallelism with TensorRT-LLM, we observed higher latency compared to tensor parallelism at the same degrees. Interestingly, when combining both parallelism strategies (PP=2, TP=2), latency decreased compared to using only pipeline parallelism, though it remained higher than the latency observed with only tensor parallelism.
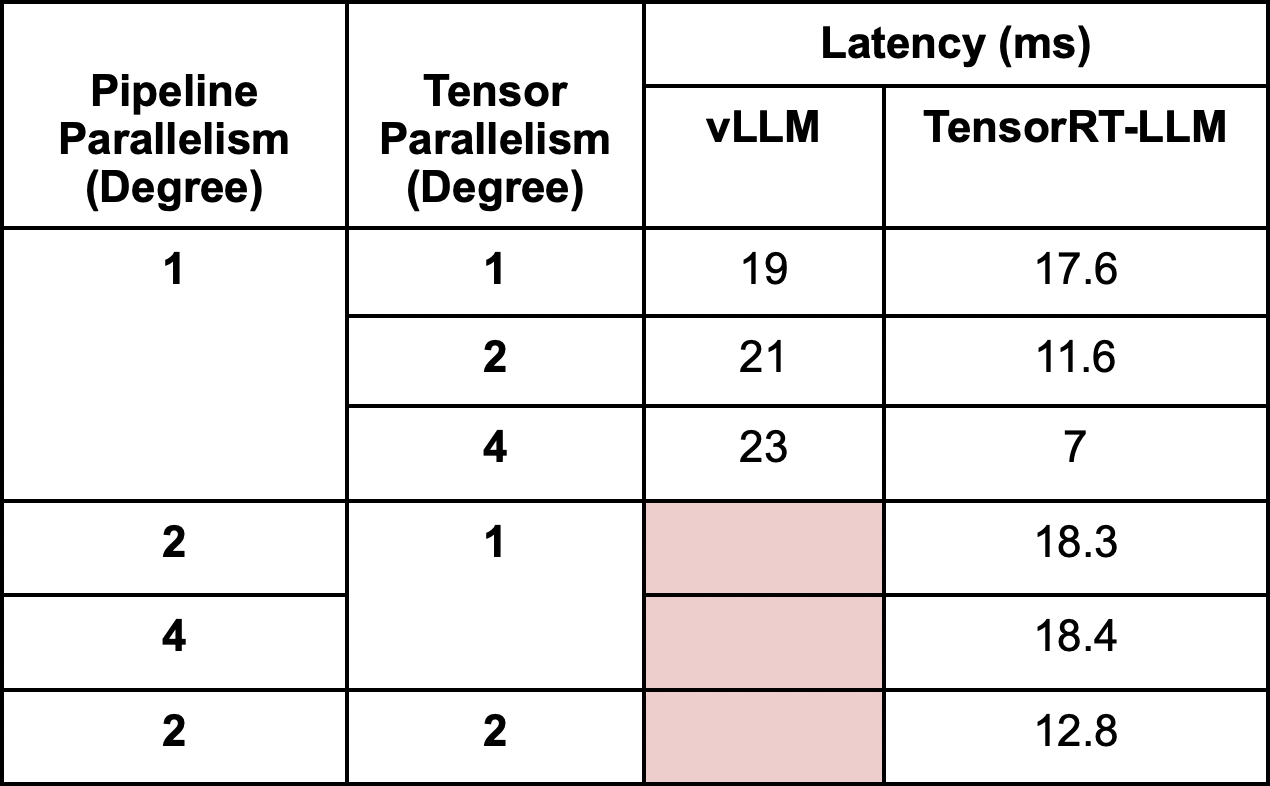
Exploring Throughput in Multi-GPU Inference
Switching our focus to throughput, we kept the input size constant at 128 to see how well the engines performed with different parallelism degrees, as outlined in Table 3. A significant finding emerged – tensor parallelism demonstrated remarkable results, more than tripling throughput when increasing the degree from 1 to 2 for both engines. The throughput continued to rise as we increased the parallelism degree to 4. However, we noted an interesting observation – our analysis revealed a non-linear relationship between the number of GPUs and throughput. Doubling the GPU count did not result in a proportional doubling of throughput, a pattern consistent across both vLLM and TensorRT-LLM.
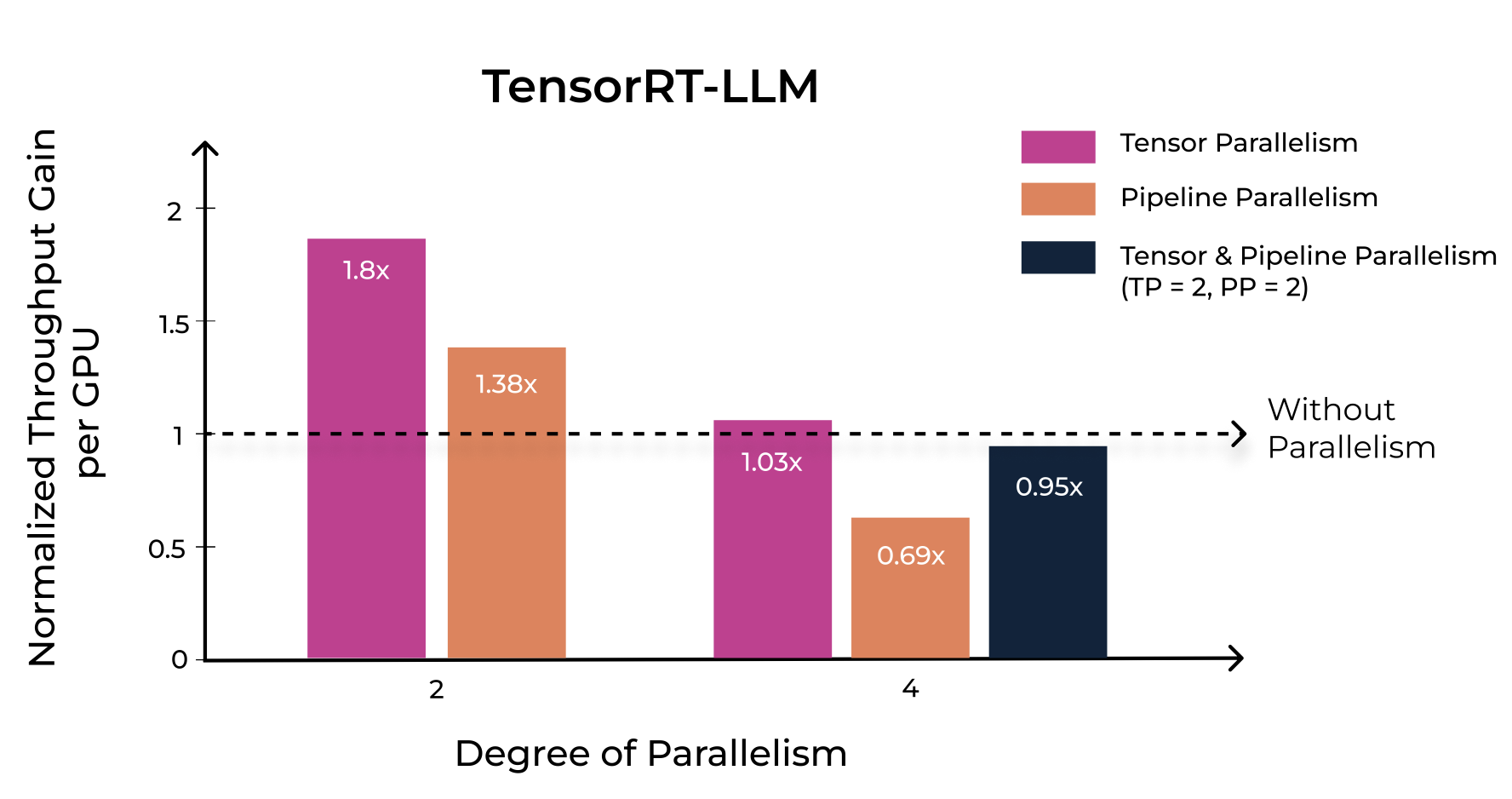
We then normalized the throughput results (see Table 4) based on the number of GPUs (the degree of parallelism) to show throughput per GPU and compare the results in a fair way. This normalization highlighted that increasing the degree of parallelism did not proportionally increase the normalized throughput per GPU. For vLLM and TensorRT-LLM throughput per GPU is improved by 57% and 80%, respectively, with Tensor Parallelism and 2 GPUs.
When comparing the throughput results of TensorRT-LLM using pipeline parallelism with those of tensor parallelism, a clear trend can be seen – tensor parallelism outperforms. When employing 4 GPUs with pipeline parallelism, the results were inferior to using 2 GPUs with tensor parallelism. Additionally, when mixing both strategies with 4 GPUs (TP = 2 and PP = 2), we nearly achieved the same results as using 2 GPUs with tensor parallelism (TP = 2). These findings underscore the importance of the chosen parallelism technique in influencing throughput.
An important note to make is that in our single-GPU experiments nvidia-smi showed a constant value of almost 100% GPU utilization. This indicates that GPU utilization is not always the right metric for examining whether performance can be squeezed from the GPU.



Key Takeaways
- Parallelism as a crucial element for enhanced inference throughput and latency: Traditionally, parallelism techniques have been a go-to strategy for scenarios where a model exceeds the capacity of a single GPU or when there's a need to accelerate the training process. However, our experiments unveil a new dimension – parallelism techniques should be considered in inference scenarios, even when the model comfortably fits within a single machine. This realization can lead to increased throughput in the memory-bound regime and decreased latency, offering significant performance improvements.
- Impact of Model Serving Implementation on Latency: Latency is significantly influenced by the choice of the implementation language of the language model. Models implemented in C++, as it is in TensorRT-LLM, exhibit reduced overhead compared to those in Python, emphasizing the importance of implementation selection in optimizing latency.
- Tensor vs. Pipeline Parallelism: Our experiments highlight that tensor parallelism outperforms pipeline parallelism in the examined use cases. Opting for fewer GPUs with tensor parallelism is more effective than deploying a larger number of GPUs with pipeline parallelism. This results in better performance and potentially reduced costs. It's crucial to note that our experiment covered a limited number of settings; therefore, pipeline parallelism might still be more advantageous for specific use cases.
- Non-linear Throughput Scaling: Increasing the GPU count doesn't guarantee a linear boost in throughput. This underscores the importance of careful resource allocation. Our normalization of throughput results reveals that doubling the GPU count might not proportionally enhance overall performance.
- Run examinations on your setup: Check your setup thoroughly to make sure it's performing at its best without breaking the bank. Compare performance across different GPU numbers, focusing on the specific metric you want to improve. Don't forget to normalize the throughput results based on the number of GPUs used. This step will help you figure out if adding more GPUs is a good move and if the performance boost justifies the extra cost. You can also start by measuring throughput for different batch sizes using a single GPU and understanding whether your case is memory or compute bound (see Figure 1). If your case is memory bound you might want to improve throughput with multi-GPU parallelism.
- Hardware Support Considerations: Different engines may require specific GPU types, underscoring the importance of hardware compatibility checks. The results and conclusions shown in this article will probably change for other GPU types.
Final thoughts
To conclude, these experiments shed light on the interplay between parallelism techniques, and hardware configurations for LLM inference. As the landscape continues to evolve, these insights offer valuable guidance for practitioners navigating the challenges of deploying large-scale language models.





