What is PyTorch GAN?
A generative adversarial network (GAN) uses two neural networks, called a generator and discriminator, to generate synthetic data that can convincingly mimic real data. For example, GAN architectures can generate fake, photorealistic pictures of animals or people.
PyTorch is a leading open source deep learning framework. While PyTorch does not provide a built-in implementation of a GAN network, it provides primitives that allow you to build GAN networks, including fully connected neural network layers, convolutional layers, and training functions.
This is part of our series of articles on deep learning for computer vision.
In this article, you will learn:
Overview
A generative adversarial network (GAN) uses two neural networks, one known as a “discriminator” and the other known as the “generator”, pitting one against the other.
Discriminator
This is a classifier that analyzes data provided by the generator, and tries to identify if it is fake generated data or real data. Training is performed using real data instances, used as positive examples, and fake data instances from the generator, which are used as negative examples.
The uses a loss function that penalizes a misclassification of a real data instance as fake, or a fake instance as a real one. With every training cycle, the discriminator updates its neural network weights using backpropagation, based on the discriminator loss function, and gets better and better at identifying the fake data instances.
Generator
The generator learns to create fake data with feedback from the discriminator. Its goal is to cause the discriminator to classify its output as real.
To train the generator, you’ll need to tightly integrate it with the discriminator. Training involves taking random input, transforming it into a data instance, feeding it to the discriminator and receiving a classification, and computing generator loss, which penalizes for a correct judgement by the discriminator.
Experiments show that the random noise initially fed to the generator can have any distribution—to make things easy, you can use a uniform distribution.
Using the Discriminator to Train the Generator
The process used to train a regular neural network is to modify weights in the backpropagation process, in an attempt to minimize the loss function. However, in a GAN, the generator feeds into the discriminator, and the generator loss measures its failure to fool the discriminator.
This needs to be included in backpropagation—it needs to start at the output and flow back from the discriminator to the generator. It is important to keep the discriminator static during generator training.
- To train the generator, use the following general procedure:
- Obtain an initial random noise sample and use it to produce generator output
- Get discriminator classification of the random noise output
- Calculate discriminator loss
- Backpropagate using both the discriminator and the generator to get gradients
- Use these gradients to update only the generator’s weights
This will ensure that with every training cycle, the generator will get a bit better at creating outputs that will fool the current generation of the discriminator.
GAN Tutorial: Build a Simple GAN in PyTorch
This brief tutorial is based on the GAN tutorial and code by Nicolas Bertagnolli. We will create a simple generator and discriminator that can generate numbers with 7 binary digits. The real data in this example is valid, even numbers, such as “1,110,010”.
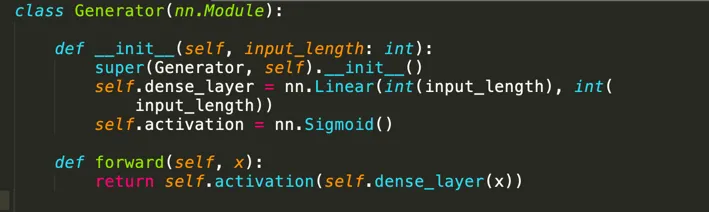
1. Building the Generator
To keep things simple, we’ll build a generator that maps binary digits into seven positions (creating an output like “0100111”). It is sufficient to use one linear layer with sigmoid activation function.
class Generator(nn.Module):
def __init__(self, input_length: int):
super(Generator, self).__init__()
self.dense_layer = nn.Linear(int(input_length), int(input_length))
self.activation = nn.Sigmoid()
def forward(self, x):
return self.activation(self.dense_layer(x))
2. Building the Discriminator
The discriminator needs to accept the 7-digit input and decide if it belongs to the real data distribution—a valid, even number. We’ll use a logistic regression with a sigmoid activation.
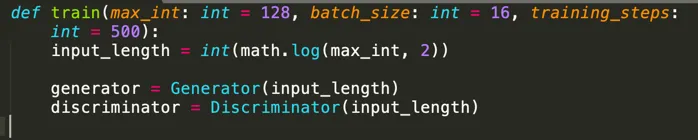
3. Training the Generator and Discriminator
We’ll start training by passing two batches to the model:
- The first is random noise
- The second contains data from the true distribution
The training function looks like this:
Defining optimizers and loss functions:

Now, for each training step, we zero the gradients and create noisy data and true data labels:
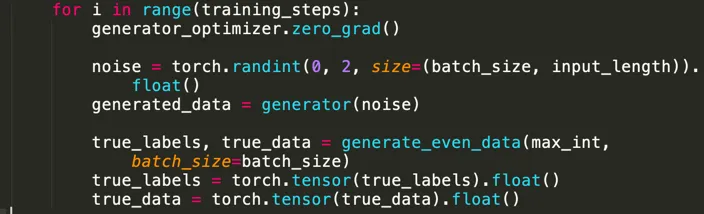
We now train the generator. This involves creating random noise, generating “fake” data, getting the discriminator to predict the label of the “fake” data, and calculating discriminator loss using labels as if the data was real.
Backpropagation is performed just for the generator, keeping the discriminator static.

We now update the weights to train the discriminator. This involves passing a batch of true data with “one” labels, then passing data from the generator, with detached weights, and “zero” labels.

Finally, we average the loss functions from two stages, and backpropagate using only the discriminator.

That’s it! The model will now be able to generate convincing 7-digit numbers that are valid, even numbers.
If you want to go beyond this “toy” implementation, and build a full-scale DCGAN with convolutional and convolutional-transpose layers, which can take in images and generate fake, photorealistic images, see the detailed DCGAN tutorial in the PyTorch documentation.
PyTorch GAN Q&A
What are Loss Functions in GAN?
GAN architectures attempt to replicate probability distributions. They use loss functions to measure how far is the data distribution generated by the GAN from the actual distribution the GAN is attempting to mimic.
A GAN typically has two loss functions:
- One for generator training
- One for discriminator training
What are Conditional GANs?
Conditional GANs can train a labeled dataset and assign a label to each created instance. For example, unconditional GAN trained on the MNIST dataset generates random numbers, but conditional MNIST GAN allows you to specify which number the GAN will generate.
What are Progressive GANs?
In a progressive GAN, the first layer of the generator produces a very low resolution image, and the subsequent layers add detail. This technique makes GAN training faster than non-progressive GANs and can produce high-resolution images.
PyTorch GAN with Run:AI
GAN is a computationally intensive neural network architecture. Run:AI automates resource management and workload orchestration for machine learning infrastructure. With Run:AI, you can automatically run as many compute intensive experiments as needed in PyTorch and other deep learning frameworks.
Here are some of the capabilities you gain when using Run:AI:
- Advanced visibility—create an efficient pipeline of resource sharing by pooling GPU compute resources.
- No more bottlenecks—you can set up guaranteed quotas of GPU resources, to avoid bottlenecks and optimize billing.
- A higher level of control—Run:AI enables you to dynamically change resource allocation, ensuring each job gets the resources it needs at any given time.
Run:AI simplifies machine learning infrastructure pipelines, helping data scientists accelerate their productivity and the quality of their models.
Learn more about the Run:AI GPU virtualization platform.

